OpenAI has significantly advanced the utility of its flagship generative AI platform, ChatGPT, by introducing a dedicated, cloud-based storage solution dubbed "Library." This innovative feature empowers users to securely house personal files, documents, and images directly within the ChatGPT ecosystem, fundamentally transforming the interactive experience from ephemeral conversations to a more persistent and context-rich engagement.
The newly launched Library serves as a centralized repository for user-uploaded content, enabling the artificial intelligence to draw upon a personalized knowledge base for future interactions. This strategic enhancement is designed to streamline workflows, improve conversational continuity, and foster a more tailored AI assistance experience. Access to this premium functionality is exclusively extended to subscribers of ChatGPT Plus, Pro, and Business tiers. While the rollout is global, it notably excludes the European Economic Area (EEA), Switzerland, and the United Kingdom, a deliberate decision likely influenced by stringent data privacy regulations prevalent in these regions.
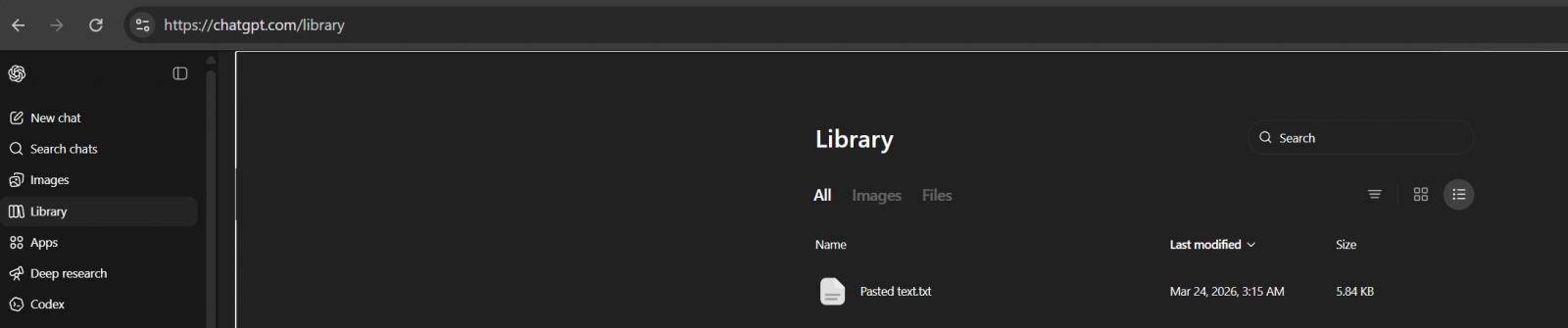
Upon activation, users accessing the ChatGPT web interface will observe the integration of the Library feature into the platform’s sidebar. A notable aspect of its implementation is its retroactive functionality; for many users, the Library will not appear as an empty repository but will already contain files uploaded during previous chat sessions. This pre-population underscores OpenAI’s proactive approach to data management, where files shared within conversations over the preceding weeks are automatically and securely archived.
This automatic saving mechanism is a core design principle of the Library. Any document, spreadsheet, presentation, or image uploaded by a user within a chat context is automatically transferred to a secure, dedicated storage location. This ensures that valuable user data is not lost with the termination of a chat session but remains accessible for subsequent reference, thereby enhancing the AI’s ability to maintain context and provide more relevant responses over time. It is important to distinguish this from AI-generated images, which continue to reside within their designated "Images" tab, maintaining a clear separation between user-supplied input and AI-created output.
The strategic rationale behind this automatic file retention is multifaceted. Primarily, it aims to cultivate a more seamless and intelligent user experience. By having continuous access to previously shared information, ChatGPT can leverage a deeper, more personal context across diverse queries and tasks. This capability is particularly beneficial for professionals engaged in ongoing projects, researchers compiling extensive data, or content creators managing iterative drafts. The AI can now serve as a more effective and informed assistant, capable of recalling specifics from past uploads without requiring users to re-upload or re-state information.
Users retain comprehensive control over their stored content within the Library. While files are automatically saved upon upload during a chat, manual management options are readily available. The interface provides clear pathways for uploading new files directly to the Library, independent of a live chat, as well as for reviewing and organizing existing content. A crucial aspect of this management framework is the distinction between chat deletion and file deletion. Erasing a conversational thread does not automatically remove the associated files from the Library; these must be manually purged by the user to ensure their complete removal from OpenAI’s servers.
Upon manual deletion by the user, OpenAI commits to purging these files from its servers within a 30-day window. The specific reasons for this month-long retention period post-deletion are not explicitly detailed but typically encompass a range of operational, legal, and compliance considerations. Such policies often allow for data recovery in case of accidental deletion, facilitate internal auditing processes, and ensure compliance with various regulatory requirements that may mandate temporary data retention, even after a user’s explicit request for removal. This period can also be crucial for managing data integrity across distributed systems and for responding to potential legal holds or investigative requests.
The introduction of the Library feature represents a significant evolution in the functional scope of large language models. Historically, AI chatbots have operated largely in a stateless manner, with each interaction treated as a fresh start unless explicitly linked through complex threading. The Library transforms ChatGPT into a more robust personal knowledge management system. For instance, a user could upload project specifications, research papers, or financial reports, and then, at any later time, instruct ChatGPT to summarize key points, analyze trends, or draft communications based on that stored information. This moves beyond simple question-answering to active collaboration with a persistent AI assistant that learns and remembers based on user-provided context.
From a strategic perspective, this enhancement positions ChatGPT more firmly as a productivity tool rather than solely a conversational agent. It broadens its appeal to enterprise users, researchers, and individuals with complex, ongoing information needs. The ability to store and reference proprietary data securely within the AI environment could unlock new use cases in areas like legal document review, scientific data analysis, and personalized learning platforms. This also signals OpenAI’s intent to create a more sticky and integrated user experience, encouraging deeper engagement and reliance on the platform for critical tasks.
However, the implementation of a persistent storage solution also amplifies critical considerations surrounding data governance, security, and privacy. Users entrusting their personal and potentially sensitive files to OpenAI’s cloud infrastructure will naturally demand robust assurances regarding data protection. OpenAI bears the responsibility for implementing stringent security measures, including encryption at rest and in transit, access controls, and regular security audits, to safeguard user data from unauthorized access or breaches. The transparency around how these stored files are used, particularly whether they contribute to future model training, is also paramount for maintaining user trust. While OpenAI typically allows users to opt out of data usage for model training, specific clarification regarding Library content would be beneficial.
The geographic exclusions – the EEA, Switzerland, and the UK – highlight the complexities of global data compliance. These regions are governed by some of the world’s most comprehensive data protection frameworks, such as the General Data Protection Regulation (GDPR) in the EEA and UK, and similar robust laws in Switzerland. These regulations impose strict requirements on data processing, storage, cross-border data transfers, explicit consent mechanisms, and the "right to be forgotten." OpenAI’s decision to initially exclude these areas suggests that the company is undertaking a meticulous process to ensure full compliance with these stringent legal requirements before a broader rollout. This could involve establishing local data centers, refining consent flows, or adapting data handling policies to meet specific regional mandates, underscoring the significant regulatory hurdles faced by global technology platforms.
Looking ahead, the ChatGPT Library has the potential for further evolution. Future enhancements could include advanced organizational features such as custom folders, tagging systems, and enhanced search capabilities to manage larger volumes of stored content more efficiently. Integration with other cloud storage services (e.g., Google Drive, Dropbox) or enterprise content management systems could also unlock greater utility and interoperability. Ultimately, the Library is a foundational step towards a future where AI assistants are not just intelligent conversationalists but highly personalized, context-aware partners, capable of actively leveraging an individual’s accumulated digital knowledge to provide unparalleled support across a myriad of personal and professional domains. This strategic move by OpenAI sets a new benchmark for AI utility, moving beyond mere interaction to genuine, persistent assistance.